
Impala 和 Kudu
来神策数据后,开始接触到Kudu和Impala两个组件,这两者的结合主要是受到 vertica 提出的 wos 和 ros 概念影响,即 写优化(write optimized store)和 读优化 (read optimized store),这一技术架构本质上就是一种数据的混合存储模型:
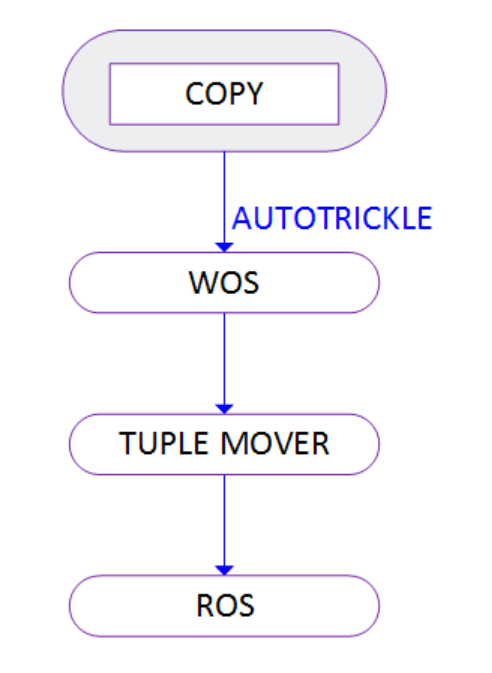
data movement
kudu在这个模型中充当wos的提供者,充当短暂、临时存储,目的就是提供快速的数据写入能力,同时还能具有一定的查询性能(3机环境单表条数5000W、3副本),parquet on hdfs 扮演 ros 的提供者,impala在大规模数据的读取时,加上合适裁剪策略,速度上还是不错的。下图体现出了kudu和parquet在写入和查询方面的速度对比。
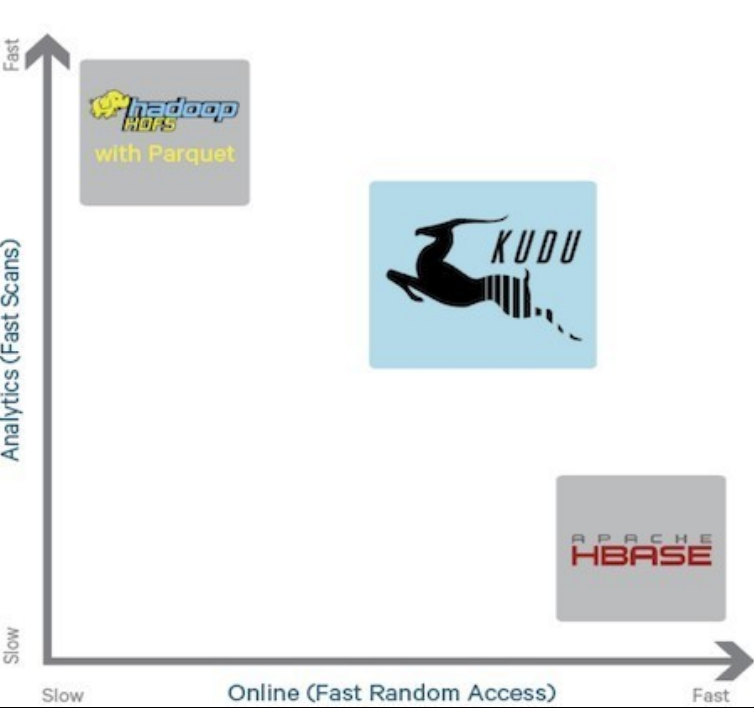
Kudu 的定位是提供”fast analytics on fast data”,也就是在快速更新的数据上进行快速的查询。它定位 OLAP 和少量的 OLTP 工作流,如果有大量的 random accesses,官方建议还是使用 HBase 更为合适。 对于更大规模的数据查询,则交给了HDFS with parquet。
关于WOS 和ROS,可以参考 vertica的两篇文章:
https://www.vertica.com/blog/understanding-ros-and-wos-a-hybrid-data-storage-modelba-p233206/
https://www.vertica.com/blog/write-optimized-storage-wos-deprecation-what-you-need-to-know/
Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断的完善中。
Impala相对于Hive所使用的优化技术
1、没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与 MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取 数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免 每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
2、使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。
3、充分利用可用的硬件指令(SSE4.2)。
4、更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum。
5、通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
6、最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
