
几种OLAP引擎简单对比
Kudu VS Clickhouse
kudu 2015年9月28号出现第一个测试版本0.5.0,2016年2月26第一个正式版0.7.发布。clickhouse 2018年3月开源正式版出现。两者都是列式存储,都可以针对数据进行实时OLAP分析,两者的区别如下:
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
ClickHouse部署架构简单,易用,不依赖Hadoop体系(HDFS+YARN)。它比较擅长的地方是对一个大数据量的单表进行聚合查询。Clickhouse用C++实现,底层实现具备向量化执行(Vectorized Execution)、减枝等优化能力,具备强劲的查询性能。目前在互联网企业均有广泛使用,比较适合内部BI报表型应用,可以提供低延迟(ms级别)的响应速度,也就是说单个查询非常快。
但是Clickhouse也有它的局限性,在OLAP技术选型的时候,应该避免把它作为多表关联查询(JOIN)的引擎,也应该避免把它用在期望支撑高并发数据查询的场景,OLAP分析场景中,一般认为QPS达到1000+就算高并发,而不是像电商、抢红包等业务场景中,10W以上才算高并发,毕竟数据分析场景,数据海量,计算复杂,QPS能够达到1000已经非常不容易。
例如Clickhouse,如果如数据量是TB级别,聚合计算稍复杂一点,单集群QPS一般达到100已经很困难了,所以它更适合企业内部BI报表应用,而不适合如数十万的广告主报表或者数百万的淘宝店主相关报表应用。Clickhouse的执行模型决定了它会尽全力来执行一个Query,而不是同时执行很多Query。
OLAP执行模型
Scatter-Gather执行模型:相当于MapReduce中的一趟Map和Reduce,没有多轮的迭代,而且中间计算结果往往存储在内存中,通过网络直接交换。Elasticsearch、Druid、Kylin都是此模型。
MapReduce:Hive是此模型
MPP:MPP学名是大规模并行计算,其实很难给它一个准确的定义。如果说的宽泛一点,Presto、Impala、Doris、Clickhouse、Spark SQL、Flink SQL这些都算。有人说Spark SQL和Flink SQL属于DAG模型,我们思考后认为,DAG并不算一种单独的模型,它只是生成执行计划的一种方式。
Presto
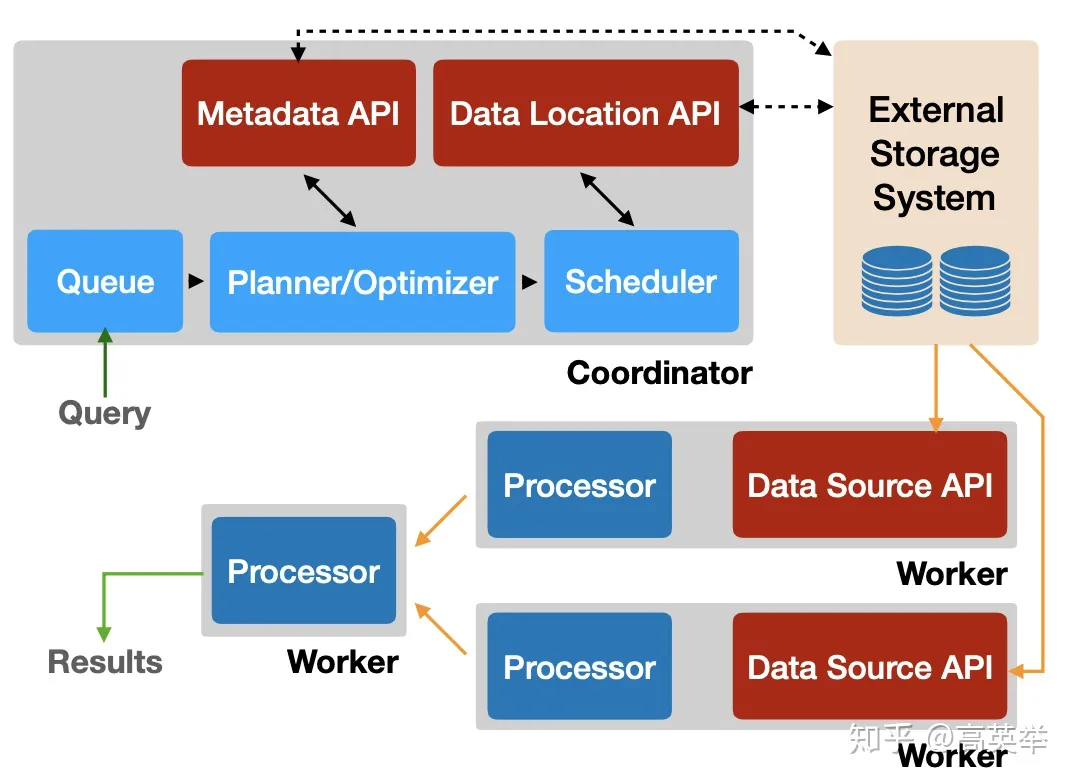
Presto、Impala、GreenPlum均基于MPP架构,相比Elasticsearch、Druid、Kylin这样的简单Scatter-Gather模型,在支持的SQL计算上更加通用,更适合ad-hoc查询场景,然而这些通用系统往往比专用系统更难做性能优化,所以不太适合做对查询QPS(参考值QPS > 1000)、延迟要求比较高(参考值search latency < 500ms)的在线服务,更适合做公司内部的查询服务和加速Hive查询的服务。Presto还有一个优秀的特性是使用了ANSI标准SQL,并且支持超过30+的数据源Connector。这里我们给读者留下一个思考题:以Presto为代表的MPP模型与Hive为代表的MapReduce模型的性能差异比较大的原因是什么?
Impala

Impala 是 Cloudera 在受到 Google 的 Dremel 启发下开发的实时交互SQL大数据查询工具,是CDH 平台首选的 PB 级大数据实时查询分析引擎。它拥有和Hadoop一样的可扩展性、它提供了类SQL(类Hsql)语法,在多用户场景下也能拥有较高的响应速度和吞吐量。它是由Java和C++实现的,Java提供的查询交互的接口和实现,C++实现了查询引擎部分,除此之外,Impala还能够共享Hive Metastore,甚至可以直接使用Hive的JDBC jar和beeline等直接对Impala进行查询、支持丰富的数据存储格式(Parquet、Avro等)。此外,Impala 没有再使用缓慢的 Hive+MapReduce 批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由 Query Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直接从 HDFS 或 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。Impala经常搭配存储引擎Kudu一起提供服务,这么做最大的优势是点查比较快,并且支持数据的Update和Delete。
Doris
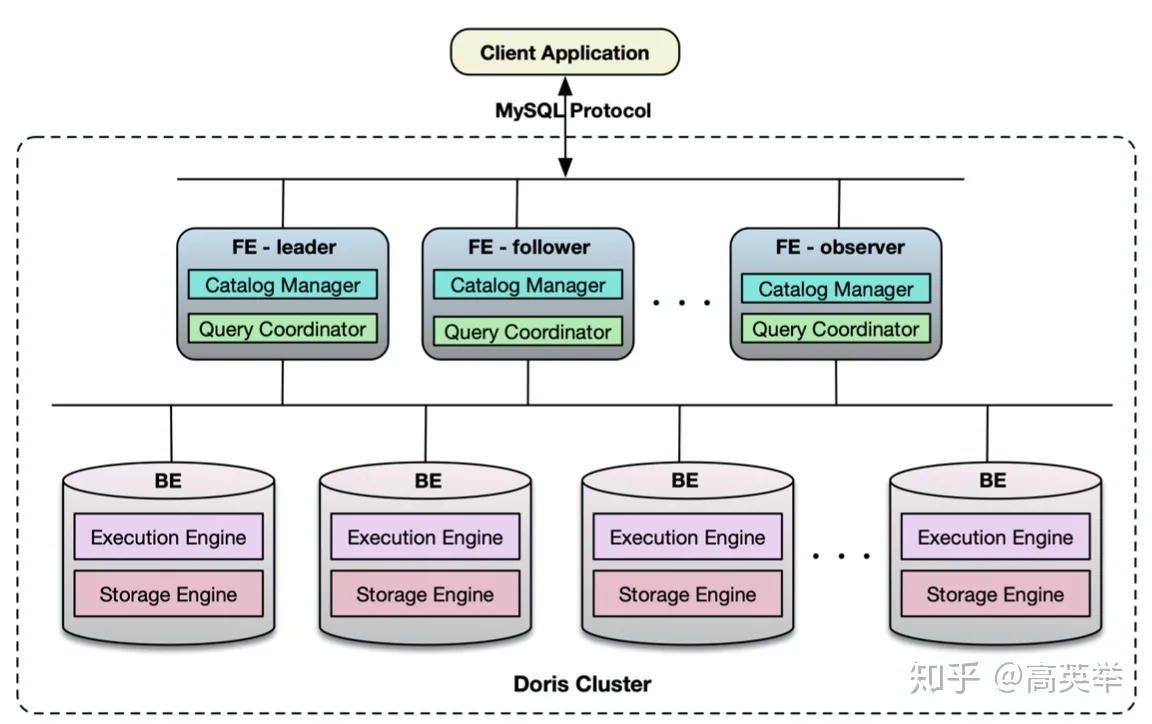
Doris是百度主导的,根据Google Mesa论文和Impala项目改写的一个大数据分析引擎,在百度、美团团、京东的广告分析等业务有广泛的应用。Doris的主要功能特性如下图所示:


Druid
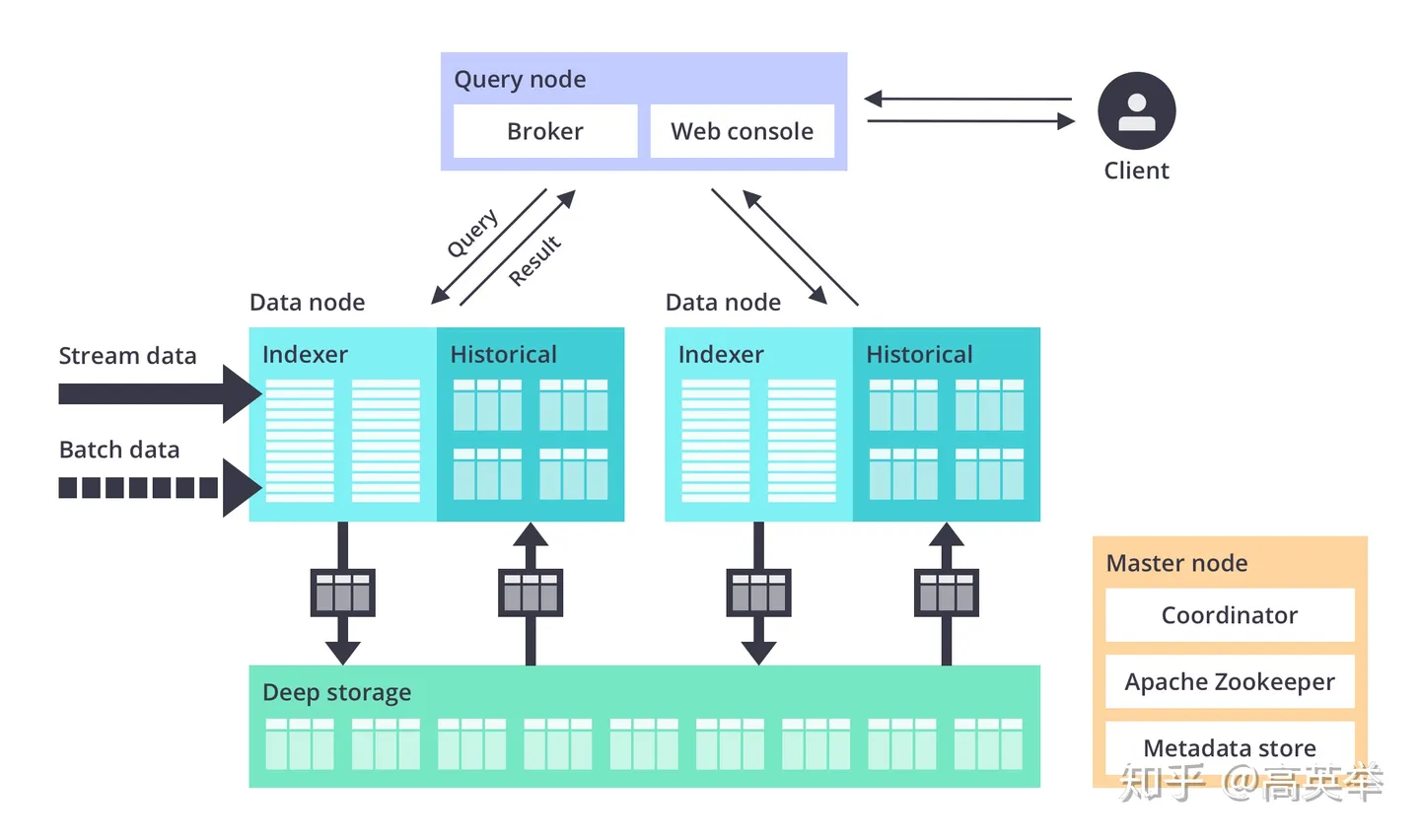
Druid 是一种能对历史和实时数据提供亚秒级别的查询的数据存储。
Druid 支持低延时的数据摄取,灵活的数据探索分析,高性能的数据聚合,简便的水平扩展。
Druid支持更大的数据规模,具备一定的预聚合能力,通过倒排索引和位图索引进一步优化查询性能,在广告分析场景、监控报警等时序类应用均有广泛使用;
Druid的特点包括:
Druid实时的数据消费,真正做到数据摄入实时、查询结果实时
Druid支持 PB 级数据、千亿级事件快速处理,支持每秒数千查询并发
Druid的核心是时间序列,把数据按照时间序列分批存储,十分适合用于对按时间进行统计分析的场景
Druid把数据列分为三类:时间戳、维度列、指标列
Druid不支持多表连接
Druid中的数据一般是使用其他计算框架(Spark等)预计算好的低层次统计数据
Druid不适合用于处理透视维度复杂多变的查询场景
Druid擅长的查询类型比较单一,一些常用的SQL(groupby 等)语句在druid里运行速度一般
Druid支持低延时的数据插入、更新,但是比hbase、传统数据库要慢很多
与其他的时序数据库类似,Druid在查询条件命中大量数据情况下可能会有性能问题,而且排序、聚合等能力普遍不太好,灵活性和扩展性不够,比如缺乏Join、子查询等。
Kylin
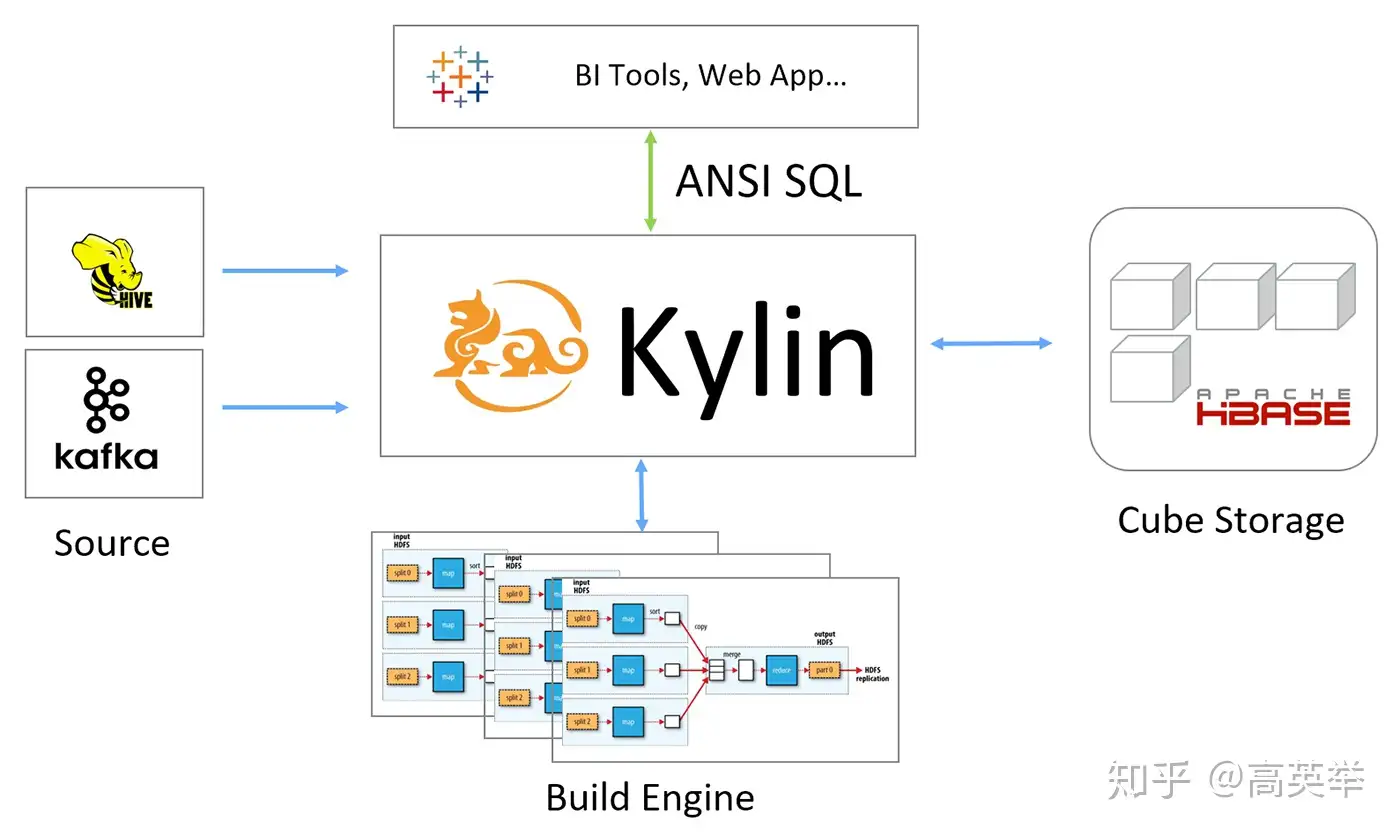
Kylin自身就是一个MOLAP系统,多维立方体(MOLAP Cube)的设计使得用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体进行数据的预聚合。
适合Kylin的场景包括:
用户数据存在于Hadoop HDFS中,利用Hive将HDFS文件数据以关系数据方式存取,数据量巨大,在500G以上
每天有数G甚至数十G的数据增量导入
有10个以内较为固定的分析维度
简单来说,Kylin中数据立方的思想就是以空间换时间,通过定义一系列的纬度,对每个纬度的组合进行预先计算并存储。有N个纬度,就会有2的N次种组合。所以最好控制好纬度的数量,因为存储量会随着纬度的增加爆炸式的增长,产生灾难性后果。
