
冷热数据分离 | Alluxio元数据管理策略
一.Alluxio概述
Alluxio(前身Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。
Alluxio项目源自加州大学伯克利分校AMPLab,作为伯克利数据分析堆栈(BDAS)的数据访问层。Alluxio是增长最快的开源项目之一,吸引了来自300多家机构的1000多名贡献者,包括阿里巴巴,Alluxio,百度,CMU,谷歌,IBM,英特尔,NJU,红帽,腾讯,加州大学伯克利分校,以及雅虎。
本文我们就来简单聊聊Alluxio的tier layer的元数据管理。
当元数据管理再进一步加大的时候,我们还能如何拓展单个节点元数据管理能力的极限呢?比如从支持百万级别量级文件到数十亿级别体量文件。将数十亿级别量级文件元数据全部load到机器内存已经是一件不太靠谱的做法了。这个时候我们有一种新的元数据管理系统模式:分层级的元数据管理,官方术语的称呼叫做Tier layer的元数据管理。
这里主要分为两种layer:
最近访问的热点元数据,做内存缓存,叫做cached layer。
很久没有访问过的数据((也可称作冷数据),做持久化保存存,叫做persisted layer。
热点数据和冷数据根据用户的访问频率行为可以互相之间做转换,类似如下所示: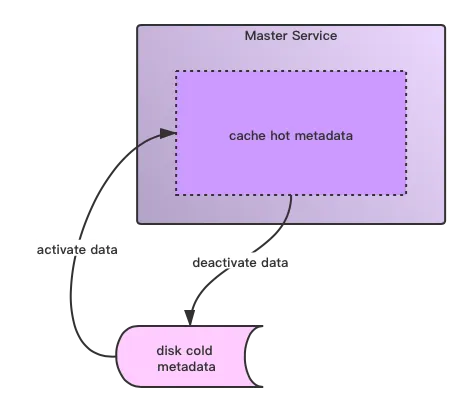
在此模式系统下,服务只cache当前active的数据,所以也就不会有内存瓶颈这样的问题。
Alluxio内部元数据管理架构
相比较于将元数据全部load到memory然后以此提高快速访问能力的元数据管理方式,Alluxio在这点上做了优化改进,只cache那些active的数据,这是其内部元数据管理的一大特点。对于那些近期没有访问过的冷数据,则保存在本地的rocksdb内。
在Alluxio中,有专门的定义来定义上述元数据的存储,在内存中cache active数据的存储层,我们叫做cache store,底层rocksdb层则叫做baking store。
Alluxio就是基于上面提到的2层store做数据数据然后对外提供数据访问能力,架构图如下所示:
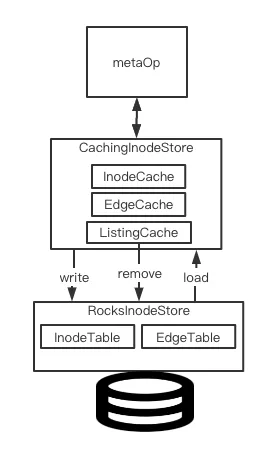
本文笔者这里想重点聊的点在于Cache store如何和上面Rocks store(Baking store)进行数据交互的。
Alluxio的支持异步写出功能的自定义Cache实现
在Cache store层,它需要做以下2件事情来保证元数据的正常更新:
及时将那些访问频率降低的热点数据移除并写出到baking store里去。
有新的数据访问来时,将这些数据从baking store读出来并加载到cache里去。
在上面两点中,毫无疑问,第一点是Alluxio具体要实现。那么Alluxio采用的是什么办法呢?用现有成熟Cache工具,guava cache?Guava cache自带expireAfterAccess能很好的满足上述的使用场景。
不过最终Alluxio并没有使用Guava cahce的方案。这点笔者认为主要的一点在于guava cahce不支持异步的entry过期写出功能。Gauva cache在更新过期entry时并没有开启额外线程的方式来做过期entry的处理,而是放在了后面的每次的cache访问操作里顺带做了。那么这里其实会有一个隐患:当cache很久没有被访问过了,然后下一次cache访问发生在已经超过大部分entry的过期时间之后,那么这时候可能会触发大量的cache更新重新加载的行为。此时Guava Cache本身将会消耗掉很多的CPU来做这样的事情,这也势必会影响Cache对外提供数据访问的能力。另外一点,Gauva Cache的entry更新是要带锁的,如果Cache entry更新的缓慢是会block住其它想要访问此entry的thread的。
结论是说,如果我们想要Cache entry能够被及时的移除以及更新,可以自己实现一个thread来触发更新的行为。下面是Guava cache的Git文档对这块的一个说明解释,里面也提到了为什么Guava Cahce为什么不在内部实现启动线程来做cache过期更新的原因:
OK,下面我们就来看看Alluxio内部实现的带异步写出outdated entry功能的cache实现。这里我们对着其代码实现做具体阐述。
首先是上面架构图中的CachingInodeStore的定义:
这里我们主要看mInodeCache这个cache,它保存了最近访问过的inode。
我们看到InodeCache底层继承的是Cache<K, V>这个类,我们继续进入这个类的实现:
简单而言,Alluxio的Cache类工作的本质模式是一个ConcurrentHashMap+EvictionThread的模式。因为涉及到Map并发操作的情况,所以这里使用了ConcurrentHashMap。然后再根据这里阈值的定义(高低watermark值的设定),进行entry的写出更新。
下面我们直接来看EvictionThread的操作逻辑:
继续进入evictToLowWaterMark方法:
上面fillBatch的entry数收集过程如下所示:
然后是entry写出操作:
我们可以看到entry移除的过程其实还会被分出两类,这其中取决于此entry值和baking store中持久化保存的值是否一致。
第一类,只需从cache map中进行移除
第二类,从cache map中进行移除,还需要写出到baking store。
这里是由cache Entry的dirty属性值来确定的:
evictBatch的flushEntries方法取决于继承子类如何实现baking store的写出。
Map entry的异步写出过期entry过程说完了,我们再来看另一部分内容Entry的访问操作get/put, delete的操作。
这里我们以put操作为例:
在上面方法的最后一行逻辑,会第一时间激活Eviction线程来做entry的移除操作,这样就不会存在前文说的短期内可能大量entry的写出移除操作了。这点和Guava cache的过期更新策略是不同的。
以上就是本文所讲述的主要内容了,其中大量篇幅介绍的是Alluxio内部Cache功能的实现,更详细逻辑读者朋友们可阅读下文相关类代码的链接进行进一步的学习。
引用
[1].https://github.com/google/guava/wiki/CachesExplained#refresh
[2].https://dzone.com/articles/scalable-metadata-service-in-alluxio-storing-billi
[3].https://dzone.com/articles/store-1-billion-files-in-alluxio-20

